"To unlock the power of data while also respecting respondent privacy, those providing access to data must navigate the fundamental tension between scientific benefits and risk to respondents."
This blog post summarizes a paper describing the privacy and ethics process by which we organized the Fragile Families Challenge. The paper will appear in a special issue of the journal Socius.
Academic researchers, companies, and governments holding data face a fundamental tension between risk to respondents and benefits to science. On one hand, these data custodians might like to share data with a wide and diverse set of researchers in order to maximize possible benefits to science. On the other hand, the data custodians might like to keep data locked away in order to protect the privacy of those whose information is in the data. Our paper is about the process we used to handle this fundamental tension in one particular setting: the Fragile Families Challenge, a scientific mass collaboration designed to yield insights that could improve the lives of disadvantaged children in the United States. We wrote this paper not because we believe we eliminated privacy risk, but because others might benefit from our process and improve upon it.
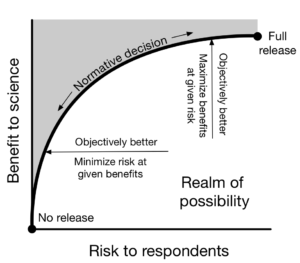
One scientific objective of the Fragile Families Challenge was to maximize predictive performance of adolescent outcomes (i.e. high school GPA) measured at approximately age 15 given a set of background variables measured from birth through age 9. We aimed to do so using the Common Task Framework (see Donoho 2017, Section 6): we would share data with researchers who would build predictive models using observed outcomes for half of the cases (the training set).
These researchers would receive instant feedback on out-of-sample performance in ⅛ of the cases (the leaderboard set) and ultimately be evaluated by performance in ⅜ of the cases which we would keep hidden until the end of the Challenge (the holdout set). If scientific benefit was the only goal, the optimal design might be to include every possible variable in the background set and share with anyone who wanted access with no restrictions.

Scientific benefit may be maximized by sharing data widely, but risk to respondents is also maximized by doing so. Although methods of data sharing with provable privacy guarantees are an active area of research, we believed that solutions that could offer provable guarantees were not possible in our setting without a substantial loss of scientific benefit (see Section 2.4 of our paper). Instead, we engaged in a privacy and ethics process that involved threat modeling, threat mitigation, and third-party guidance, all undertaken within an ethical framework.
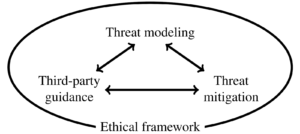
Threat Modeling
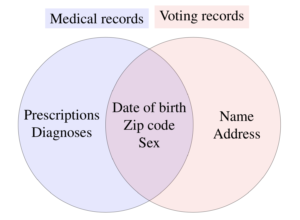
Our primary concern was a risk of re-identification. Although our data did not contain obvious identifiers, we worried that an adversary could find an auxiliary dataset containing identifiers as well as key variables also present in our data. If so, they could link our dataset to the identifiers (either perfectly or probabilistically) to re-identify at least some rows in the data. For instance, Sweeney was able to re-identify Massachusetts medical records data by linking to identified voter records using the shared variables zip code, date of birth, and sex. Given the vast number of auxiliary datasets (red) that exist now or may exist in the future, it is likely that some research datasets (blue) could be re-identified. It is difficult to know in advance which key variables (purple) may aid the adversary in this task.
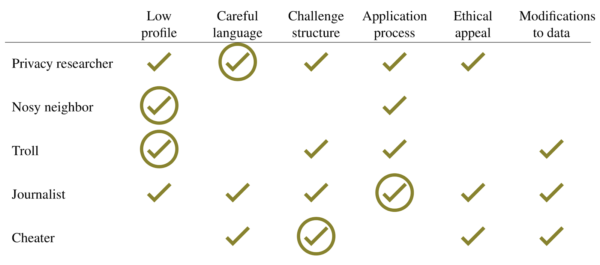
To make our worries concrete, we engaged in threat modeling: we reasoned about who might have both (a) the capability to conduct such an attack and (b) the incentive to do so. We even tried to attack our own data. Through this process we identified five main threats (the rows in the figure below). A privacy researcher, for instance, would likely have the skills to re-identify the data if they could find auxiliary data to do so, and might also have an incentive to re-identify, perhaps to publish a paper arguing that we had been too cavalier about privacy concerns. A nosy neighbor who knew someone in the data might be able to find that individual’s case in order to learn information about their friend which they did not already know. We also worried about other threats that are detailed in the full paper.
Threat Mitigation
To mitigate threats, we took several steps to (a) reduce the likelihood of re-identification and to (b) reduce the risk of harm in the event of re-identification. While some of these defenses were statistical (i.e. modifications to data designed to support aims [a] and [b]), many instead focused on social norms and other aspects of the project that are more difficult to quantify.
For instance, we structured the Challenge with no monetary prize, to reduce an incentive to re-identify the data in order to produce remarkably good predictions. We used careful language and avoided making extreme claims to have “anonymized” the data, thereby reducing the incentive for a privacy researcher to correct us. We used an application process to only share the data with those likely to contribute to the scientific goals of the project, and we included an ethical appeal in which potential participants learned about the importance of respecting the privacy of respondents and agreed to use the data ethically.
None of these mitigations eliminated the risk, but they all helped to shift the balance of risks and benefits of data sharing in a way consistent with ethical use of the data. The figure below lists our main mitigations (columns), with check marks to indicate the threats (rows) against which they might be effective. The circled check mark indicates the mitigation that we thought would be most effective against that particular adversary.
Third-Party Guidance
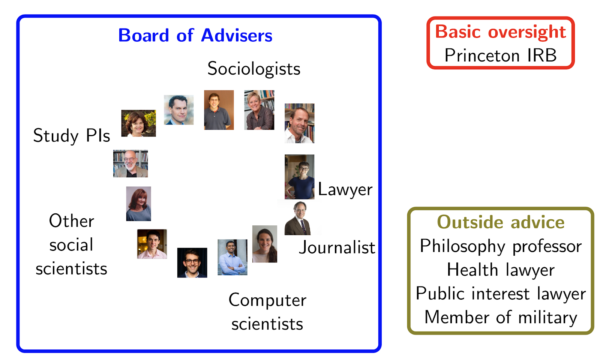
A small group of researchers highly committed to a project can easily convince themselves that they are behaving ethically, even if an outsider would recognize flaws in their logic. To avoid groupthink, we conducted the Challenge under the guidance of third parties. The entire process was conducted under the oversight and approval of the Institutional Review Board of Princeton University, a requirement for social science research involving human subjects. To go beyond what was required, we additionally formed a Board of Advisers to review our plan and offer advice. This Board included experts from a wide range of fields.
Beyond the Board, we solicited informal outside advice from a diverse set of anyone we could talk to who might have thoughts about the process, and this proved valuable. For example, at the advice of someone with experience planning high-risk operations in the military, we developed a response plan in case something went wrong. Having this plan in place meant that we could respond quickly and forcefully should something unexpected have occurred.
Ethics
After the process outlined above, we still faced an ethical question: should we share the data and proceed with the Fragile Families Challenge? This was a deep and complex question to which a fully satisfactory answer was likely to be elusive. Much of our final decision drew on the principles of the Belmont Report, a standard set of principles used in social science research ethics. While not perfect, the Belmont Report serves as a reasonable benchmark because it is the standard that has developed in the scientific community regarding human subjects research.
The first principle in the Belmont Report is respect for persons. Because families in the Fragile Families Study had consented for their data to be used for research, sharing the data with researchers in a scientific project agreed with this principle. The second principle is beneficence, which requires that the risks of research be balanced against potential benefits. The threat mitigations we carried out were designed with beneficence in mind. The third principle is justice: that the benefits of research should flow to a similar population that bears the risks.
Our sample included many disadvantaged urban American families, and the scientific benefits of the research might ultimately inform better policies to help those in similar situations. It would be wrong to exclude this population from the potential to benefit from research, so we reasoned that the project was in line with the principle of justice. For all of these reasons, we decided with our Board of Advisers that proceeding with the project would be ethical.
Conclusion
To unlock the power of data while also respecting respondent privacy, those providing access to data must navigate the fundamental tension between scientific benefits and risk to respondents. Our process did not offer provable privacy guarantees, and it was not perfect. Nevertheless, our process to address this tension may be useful to others in similar situations as data stewards.
We believe the core principles of threat modeling, threat mitigation, and third-party guidance within an ethical framework will be essential to such a task, and we look forward to learning from others in the future who build on what we have done to improve the process of navigating this tension.
You can read more about our process in our pre-print: Lundberg, Narayanan, Levy, and Salganik (2018) “Privacy, ethics, and data access: A case study of the Fragile Families Challenge.”